|
Voice Coding Algorithms
There are several approaches to digitizing
the voice samples. These approaches vary by the information that
is transmitted, the complexity of the algorithm, and the assumptions
of the sound being transmitted (e.g. voice, fax, music). Broadly
classified, the various coding algorithms fall into two broad
categories: coding of waveform and modeling of the vocal track.
Pulse Code Modulation and Sub Band Coding are examples of waveform
coding algorithms while Linear Predictive Coding is an example
of an algorithm that models the vocal tract.
The Pulse Code Modulation (PCM) algorithm makes no assumptions
about the sound that is being digitized and therefore does the
best job on various types of sounds. It also produces the highest
bit-rate for the data and has the shortest delay. The basics of
the various PCM algorithms is that the voice is sampled at fixed
time intervals (i.e. 8,000 times/second) and then a number is
generated from the data based on each sample.
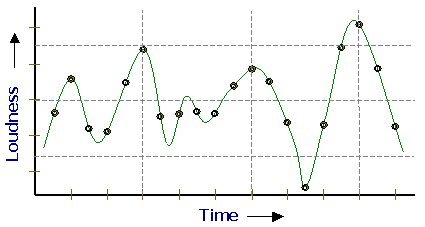
Figure 1. PCM algorithms sample the voice at fixed
time intervals
ADPCM (Adaptive Differential Pulse Code
Modulation), a variant of PCM, samples the voice at fixed time
intervals and then calculates the change from the previous sample
and sends that information. To save bandwidth, these step sizes
are specially coded so that the step size at low volume is different
than the step size at high volume. ADPCM provides about a 2:1
reduction in the data compared to PCM.
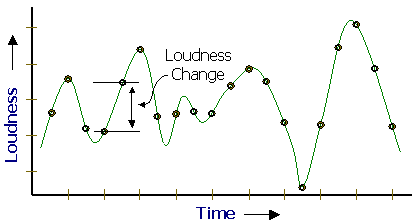
Figure 2. ADPCM codes the change in amplitude
A second approach to waveform coding
is to digitally represent sounds using the frequency of the sounds.
Instead of sampling the waveform in fixed units of time, the sound
is represented in units of frequency. This works well for speech
since vowels are low frequency and consonants are high frequencies.
This type of algorithm is called a Sub Band Coder (SBC) and a
spectrograph of speech using frequency is shown in Figure 3.
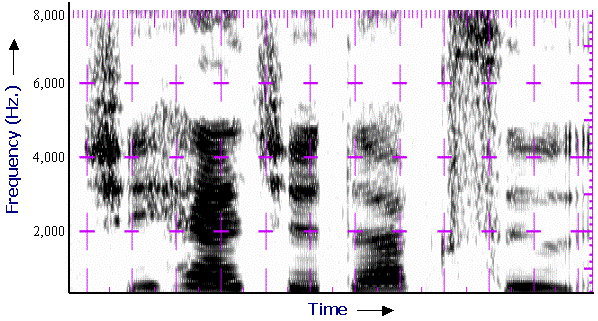
Figure 3. SBC uses frequencies of the voice sample
Another way to sample speech is to use
a model of the way people generate speech. In the Linear Predictive
Coding (LPC) algorithm, the human vocal tract is modeled. Humans
have an excitation source at the source of the vocal tract and
muscles along the tube is constricted which, in effect, shapes
the waveform. People change the constriction points to make the
various sounds (i.e. tongue and lip movement). LPC uses a series
of filters that accomplish a similar function.
Sound reproduction can be very good and its performance is primarily
limited by how well the excitation waveform can be reproduced.
In the LPC algorithm, the filter coefficients and the excitation
type are all that is needed to be transmitted which can be significantly
less than the amount of information need to be transmitted for
PCM methods.
The reduced bandwidth requirements of LPC come at the expense
of the large amount of processing power necessary for the algorithm.
LPC works well for sending human speech sounds, not very well
for music and it does not work at all for transmitting fax (or
computer modem) sounds.
There are also algorithms that use a mixture of these algorithms
and produces adequate sound quality with medium bit rates. An
example of such a hybrid coder is CELP.
Coding Standards
There are a number of voice coding standards
and the ITU is the most active of the groups in this area. For
information on the details of any of these standards, go to the
ITU web site (www.itu.int/ITU-T
).
Table 1 provides a summary of several of the major voice coding
algorithms. As can be seen, there is a range of data rates available.
The column labeled MOS (Mean Opinion Score), is a subjective score
that listeners give to each of these algorithms. For point of
reference, G.711 is what is used in the US phone system.
Table 1. Voice
Coding Standards
|
Algorithm
|
Bit
Rate
(Kbits/sec)
|
Complexity
(Mips)
|
Delay
(milliseconds)
|
MOS
|
|
G.711 PCM
|
64
|
< 1
|
.25
|
4.4
|
|
G.723.1 MPMLQ
|
6.3
|
18
|
30
|
3.9
|
|
G.723.1 ACELP
|
5.3
|
18
|
30
|
3.6
|
|
|
32
|
1
|
.25
|
4.2
|
|
|
16
|
30
|
3 - 5
|
4.2
|
|
|
8
|
20
|
10
|
4.2
|
|
|
13.2
|
4.5
|
40
|
3.7
|
The complexity column of the above table is an indication of how
complex the algorithm is to implement in a Digital Signal Processor
(DSP). The exact value is not as important as is the relative
numbers between the various algorithms.
G.711 (PCM)
G.711 (PCM: Pulse code modulation) is
an international standard and widely used in the conversion of
analog voice signals for use in digital transmission networks.
The G.711 quality and characteristics are widely used as a reference
point when new or improved algorithms are used in testing. Two
sub-methods exist, mu-law (US) and A-law (non-US). G.711
has a 64 kbits/second data rate.
G.722 (SB-ADPCM)
The G.722 wideband speech coding algorithm
uses SB-PCM (Sub-Band Adaptive Differential Pulse Code Modulation)
and supports bit rates of 64, 56 and 48 kbps. The codec can be
integrated on one chip and its overall delay is around 3 ms, small
enough to cause no echo problems in telecommunication networks.
In addition, this algorithm provides acceptable performance (maintains
its intelligibility) for transmission bit error rates up to 10-3.
G.722 divides the 16 kHz sampled voice into two overlapping frequency
bands. The coding of the sub-band signal is based on a modified
version of ADPCM. Input samples in each band are adaptively predicted,
quantized and transmitted.
High quality coding with the G.722 wideband speech coder is provided
by a fixed bit allocation, where the low and high sub-bands ADPCM
coders use a 6 bits/sample and 2 bits/sample quantizer, respectively.
In the low sub-band the signal resembles the narrow-band speech
signal in most of its properties and a high SNR in the lower band
becomes perceptually more important than in the higher band.
G.723.1
ITU-T G.723.1 (G.721 + G.723 combined)
produces digital voice compression levels of 20:1 and 24:1. It
operates at 6.3 kbps and 5.3 kbps respectively. The only difference
between these two transmission speeds is the amount of horsepower
needed from the CPU.
The low bandwidth requirement is ideal for real time Internet
telephony and usage over POTS-PSTN lines. G.723.1 has become one
emerging standard for cross platform interoperability regarding
the transmission of voice. Tests have shown acceptable quality
with at 1/10 of the bandwidth compared to PCM.
The algorithm complexity is one that can be implemented in a PC.
Combining this with the low bit rate, G.723.1 is the default low
bit rate audio coder for the overall H.323 video conferencing
standard.
G.726
ADPCM is able to provide good quality
speech for bit rates of 32 Kbits/s. ADPCM has been standardized
for bit rates of 16, 24, 32 and 40 Kbits/s. The ADPCM algorithm
is different from PCM because of just sampling the voice data,
the difference between the sampled voice data and the predicted
speech signal is sent. With good prediction, the difference between
the actual voice data and the predicted data will be small.
The adaptive quantizer does not have uniform step sizes. ADPCM
can be changed to accommodate other sound characteristics besides
voice.
G.728 (LD-CELP)
LD-CELP (Low Delay Code Excited Linear
Prediction) is a European ITU-T variant of US federal standard
1016 for CELP. LD-CELP digitizes 4 KHz speech at 16 Kbps and low
delay.
CELP divides the speech it is to code into 30ms frames, each of
which is further divided into four 7.5 ms sub-frames. For each
frame, the encoder calculates a set of 10 filter coefficients
for the short-term synthesis filter that is used to model the
vocal tract of the speaker. The excitation for this filter is
determined for each sub-frame, and is given by the sum of scaled
entries from two codebooks. An adaptive codebook is used to model
the long-term periodicities present in voiced speech, and for
each sub-frame, an index and a gain is determined for this codebook.
There is a fixed codebook containing 512 pseudo-random codes that
is also searched to find the codebook entry that minimizes the
error between the reconstructed and the original speech samples.
At the decoder, the scaled entries from the two codebooks are
passed through the synthesis filter to give the reconstructed
speech. Finally, this speech is passed through a post filter to
improve its perceptual quality.
G.729 (A) (CS-ACELP)
G.729 uses CS-ACELP coding (Conjugate
Structure Algebraic Code Excited Linear Prediction) at 7 KHz at
8 Kbps with a frame size is 10 ms. CS-ACELP is just of a form
of Linear Predictive Coding mentioned previously
I-30036 (GSM)
The GSM full rate speech codec operates
at 13 kbits/s and uses a Regular Pulse Excited (RPE) codec. Basically
the input speech is sampled at a 8 KHz sample-rate, split up into
frames 20 ms long, and for each frame a set of 8 short term predictor
coefficients are found. Each frame is then further split into
four 5 ms sub-frames, and for each sub-frame the encoder finds
a delay and a gain for the codec's long term predictor. Finally
the residual signal after both short and long term filtering is
quantized for each sub-frame as follows.
The 40 sample residual signal is decimated into three possible
excitation sequences, each 13 samples long. The sequence with
the highest energy is chosen as the best representation of the
excitation sequence, and each pulse in the sequence has its amplitude
quantized with three bits. At the decoder the reconstructed excitation
signal is fed through the long term and then the short term synthesis
filters to give the reconstructed speech. A post filter is used
to improve the perceptual quality of this reconstructed speech.
The GSM codec generates good quality for speech, but the G.728
codec (CELP) still outperforms the GSM algorithm slightly with
the higher rate. GSM codec is lighter, and can be run without
DSP or special audio hardware in real-time.
More Information
Additional VoIP seminars:
 An Introduction to VoIP - An overview of the VoIP technology,
architecture, and the interconnection issues.
An Introduction to VoIP - An overview of the VoIP technology,
architecture, and the interconnection issues.
VoIP Applications - The VoIP technology only becomes
useful when compelling applications meet the needs of customers.
The corporate, cable telephony, and video conferencing applications
are examined.
VoIP Problems - Deployment of VoIP has been slower
than expected because of problems with underlying networks, standardization
issues, and network control devices.
In Summary:
-
There are different voice coding standards that
provide tradeoffs in network bandwidth and computational complexity.
-
Of the major voice coding algorithms, only G.711
can carry fax and modem signals.
-
The voice coding algorithms with the lowest bandwidth
work because of knowledge of the speech producing model and
therefore do not work well on music..
|
